前回のVanishing Component Analysisに関する記事が思いのほか好評だったようで, なんか自分に対してのハードルあげちゃった感あったり,記事冒頭でデブとか書くんじゃなかった・・・(ハハハ)と後悔してたり...
いつもどおり肩肘はらずに書きますね.例によって,マンスリー読み会で紹介した論文について.
- “Joint Modeling of a Matrix with Associated Text via Latent Binary Features” XianXing Zhang and Lawrence Carin , NIPS 2012.
行列と,その列or行に紐づいたテキストが存在するときに,行列をいかによくモデル化するか,というお話です.推薦システム界隈ではわりとよくある感じの話ではあると思うのですが,適用しているデータが面白かったので紹介.
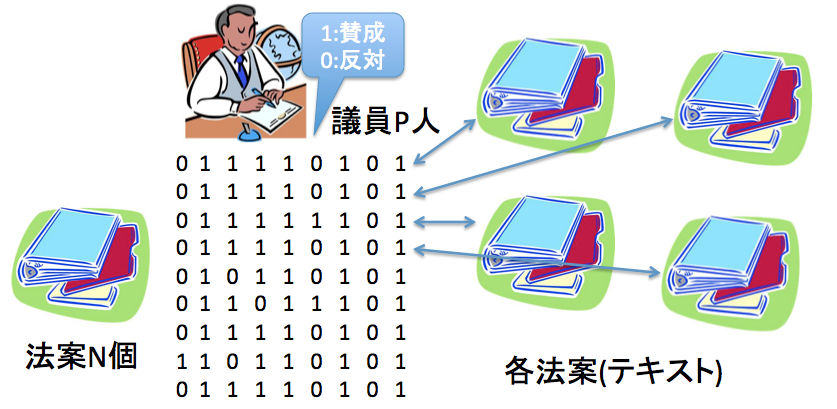
なんと,アメリカ下院議員の(法案に対する)投票行動をモデル化しています.この問題ならではの面白い性質を使っているのかと思いながら読み進めたら実はそんなことも無くて肩透かしを食らった感じではあるのですが.
法案が議会を通過するか(採択されるか)を予測する,というタスクでは,法案のテキストだけが与えられた状況で,90%以上の正解率を達成しています. この数値が高いのか低いのか私には判断がつきかねる(そもそも,提出された法案がほとんど採択されるような状況では予測の意味が無い)ものの,かなり工夫の施された他手法に比べてもそれなりに高い性能を達成しているようです. 特に政治ドメインならではのモデリングを行っているわけではなく,かなりGeneralなモデルなのですが,たとえば,政治に特化した工夫がなされたIdeal Point Topic Model(IPTM)のような既存手法に比べても高い性能,というのはなかなか面白いところです.
割とよくある推薦システムの技術が,議会という,民主主義の根幹を担うおそらく極めて高度なシステムを,表面的にではあるもののエミュレーションできてしまう,というのはなかなか考えさせられるものがあります.
今回の論文では,「議員の過去の投票行動と,法案のテキスト」の間の関係をモデル化しているだけなのですが,外部の情報,たとえば経済指標だとかパブリックコメントだとか,を組み込むことができるとすると(能力のある研究者がその気になれば不可能ではないとはおもいます),コンピュータが政治を行う,という時代も意外と近づいてきているのかもしれません.
は〜ディストピアっぽい.
以下,テクニカルな部分について.私は推薦システムだとかベイズモデルだとかはあんまり詳しくないので,色々間違っているかも.
この論文では,テキストをFocused Topic Modelというトピックモデル,賛否を表す行列をBinary Matrix Factorizationという行列分解モデルで表現しています.
そのうえで,全体を繋ぎあわせるようなバイナリの変数を導入して,全体を一気にMCMCで推定する,という流れ.スライドの最後にも載せておきましたが,グラフィカルモデルにいろいろアノテーションしたものを貼っておきます.小さくて見づらい場合は「名前をつけて保存」とか,よしなに扱って頂いてかまいません.青四角はハイパーパラメータです.
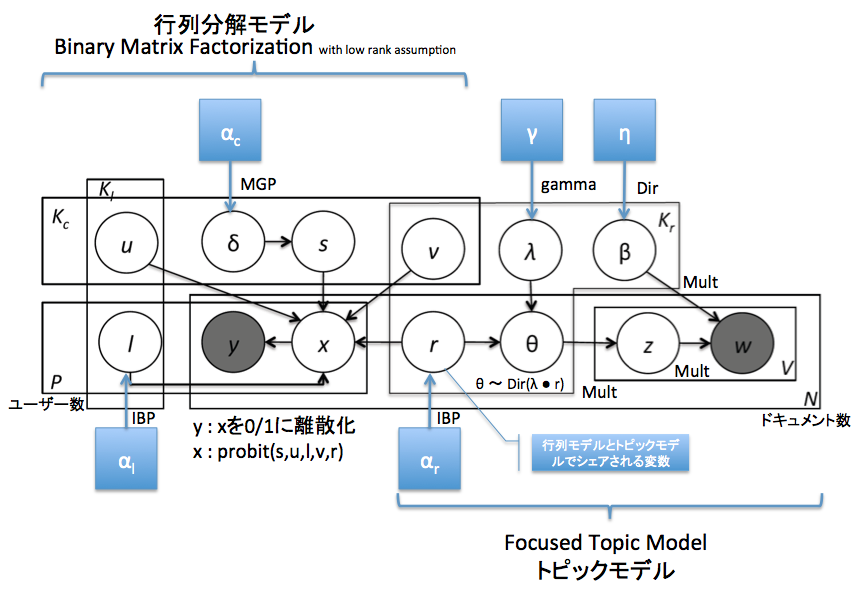
そもそも,何故Focused Topic Modelなのか,何故Binary Matrix Fctorizationなのか,という部分には,論文中にはあまり説明がなかったのですが,ちょっと考えてみたらいくつか理由付け,というか動機の推察ができたのでメモしておきます.
一つは,Focused Topic Modelの性質として,IBPから生成されるバイナリベクトルをトピック分布のサブセット選択に用いているため,トピック分布をスパースになる,というものがあります.スパースであること自体はさほど重要ではないのですが,IBPから出てくるバイナリのベクトルが,Binary Matrix Factorizationのバイナリ表現とうまくマッチする,というのは考えられそうです.両者が等価なものだとはあまり思えないのですが,複数のモデルの間にインタラクションを持たせるための確率変数としては,なかなかよい選択に思えます.
あとは,Focused Topic Modelの論文でも述べられている,コーパスレベルでのトピック生起確率と,個々のドキュメントでのトピック生起確率の相関に関する問題が,”法案”というドメインにおいては顕著に現れるという可能性もあります.私はアメリカの法律なんて読んだことないのですが,もし一つ一つの法案が(互いに語彙の重なりが少ないという意味で)専門的な文書になっているとすれば,Focused Topic Modelの利点が効いてくるのかもしれません.
しかし,これくらいごちゃごちゃしたグラフィカルモデルをまじめに読み解くのは初めてで,なかなか骨が折れました.低ランク近似の周辺なんかは未だにイマイチつかめていませんし,Inferenceのところは理解を諦めてほぼ眺めただけですが,それでもたいへん勉強になりました.
さて,読んでばっかいないで実装しろ,という声が聞こえたので今日はこのへんにて.とりあえず,ビールでも飲みに行ってきます.