先日、第36回セマンティックウェブとオントロジー研究会-DBpediaシンポジウムに出席する機会を得た。最も大きな目的はStudio Ousiaの山田さんによるエンティティリンキングに関する招待講演を聴講することだったのだが、DBpediaやその周辺環境についての研究発表やディスカッションにも興味をひかれた。
その後、DBpediaについてしばらく調べていたのだが、すこしだけまとまったので、メモとして公開することにした。
What is DBpedia?
Wikipediaを自動的に、RDFトリプルに変換する仕組み、あるいはそのプロジェクト。
できるだけ多くの項目を「あらかじめ決められた語彙」へマップすることによって、その語彙を使う他のリソースとの相互利用を進めたい、という意図がある(この動きを Linked Open Data と言うらしい)。
「自動的に変換する」と言っても、NLPの人たちが想像するような「テキストデータからの自動獲得」ではなく、Wikipediaの編集者によって構造化されたデータ(Infobox)からの取得がメイン。
RDFトリプル?
主語(subject) 述語(predicate) 目的語(object) の組の集合(大きな有向グラフとみなすことができる)で情報を表現するしくみ。詳しくはググってくだしあ。
どのように変換が行われるか
以下の図のようなイメージ。
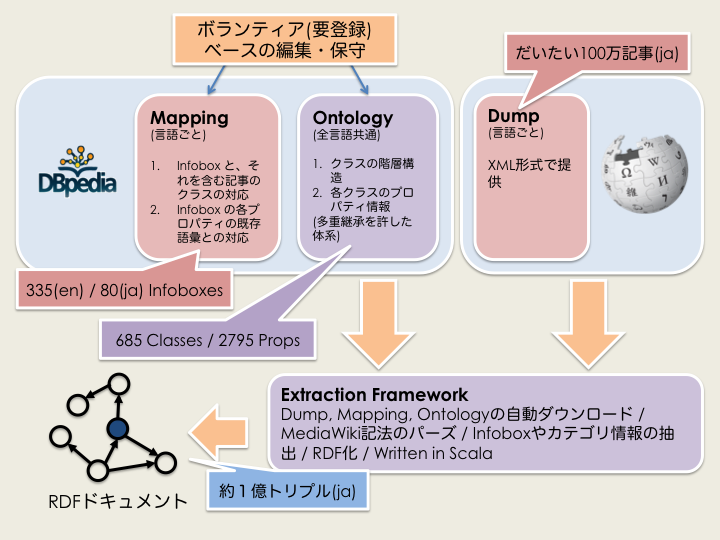
DBpediaを構築するには”Mapping”, “Ontology”, “Wikipedia Dump”の三つの情報が必要である。
先ほど述べたように、DBpediaでは、Wikipediaの項目内の情報(ほとんどはInfoboxの情報)が、主語、述語、目的語の組にマップされる。
テンプレートの各スロットが、DBpediaオントロジーの語彙のどれにあたるか、という情報が整理されたものが “Mapping” である。Mappingには、例えば、 会社 テンプレートの 代表者というスロットに記載されている情報がオントロジーで定められた keyPersonという関係の目的語になる、といった情報が書かれている。
語彙を定めるのは “Ontology”。こちらには、大別すると以下の三種類の知識が書かれている:
- 会社は組織のサブクラスである、といったカテゴリ階層に関する知識 例) http://mappings.dbpedia.org/server/ontology/classes/#Company
- 会社はスタッフ数やCEOといった属性を持つ、といったプロパティに関する知識 例) http://mappings.dbpedia.org/server/ontology/classes/Company
スタッフ数は組織に対して定義される「非負の整数」で、CEOは組織に対して定義される「人」である、といった、定義域&値域に関する知識
メタな、特定のエンティティや言語に依存しない(オントロジカルな)知識が整理されている。
これらの情報は誰でも編集ができるが、Mapping wikiにアカウントを作る、メーリングリストに挨拶メールを送る、といった手続きが必要らしい。
DBpediaにおいてマッピングが定義されていないInfobox内の情報には、適当に項目名が付与される。たとえば、空海 - Wikipedia は Buddhist という比較的マイナーなInfoboxを用いて書かれているが、現在(2015/07)はこのInfoboxに関するマッピングはDBpediaには存在しない。そのため、 http://ja.dbpedia.org/property/宗派 http://ja.dbpedia.org/property/法名 などといったプロパティが生成される。当然ながら、これらのプロパティは「野良プロパティ」とも呼べるようなもので、意味的な裏付けはあまりないと思う。
Infoboxが使われていない記事の情報は、カテゴリやリンク先などの(取れそうな情報)はとられるが、それ以外の情報は入らない。記事が指すエンティティのカテゴリも特にデータベース化はなされない。
自分の手元で変換したい
github wiki上のインストラクションに従うことで変換できる。ほとんど clone してビルドして実行するだけ。必要なデータのダウンロードも面倒をみてくれる。
DBpediaを使うにはどうすればよいか
手元にホストする必要が無い場合は、公開されているSPARQLエンドポイントを使うのがよさそう。SPARQLは、SQLライクな文法をもった問い合わせ言語。主語、述語、目的語のトリプルに対して、パターンマッチや集約を行うことができる。
手元にRDFストアを構築したい、という場合は、Openlink Virtuosoがデファクト・スタンダードみたい。導入には以下の記事が参考になった。他にもぐぐるとけっこう出てくる。
- Setting up a local DBpedia 2014 mirror with Virtuoso 7.1.0 | Jörn’s Blog
- Virtuoso Open Source Edition 7.1 on Ubuntu 12.10 - 発声練習
類似プロジェクトとの差異
よく比較される Freebase との比較をすこしだけ。Freebase はオワコンらしいが、おそらくこれらの特徴の一部はWikidataにも引き継がれるだろう。
| DBpedia | Freebase | |
|---|---|---|
| データ元 | Wikipedia。データの更新を行いたいときは、Wikipediaを更新しようという立場。 | かならずしもWikipediaにのる必要はないという立場。直接いじることができる。 |
| 運営 | ライプツィヒ大学とベルリン自由大学が起源だが、現在はDBpedia財団という組織があるらしい。日本版はNIIの武田研究室が中心となってホストしている。 | MetaWeb => Google(シャットダウン) |
| クエリ言語 | SPARQLエンドポイントが提供される | MQLなるクエリ言語がサポートされているらしいが、少し調べて見た限りではあまり使われていない印象を受ける(RDFのダンプをRDFストアに突っ込んでSPARQL等で問い合わせるか、KVSで力技、というケースが多い印象) |
その他の関連プロジェクト
- schema.org : ウェブ企業が主体となって作っている語彙体系
- Wikidata : Freebaseの後継?
- 日本語Wikipediaオントロジー : 慶応大の山口研究室によって半自動構築されたオントロジー