急に蒸し暑くなってきましたね.でぶちんなのでけっこうこたえます.タイトルはちょっと釣り気味.ビビっと来た方は是非論文に目を通してみてください:)
例によって,仲間内でやっている小さな勉強会で論文紹介をしてきましたので,そのご紹介です.ぼくの専門というか興味の中心は自然言語処理なので,ふだんはそっち方面を追っているのですが,勉強会では機械学習方面を中心にいろいろ読んでみてます.
今回は岡野原さんのこのツイートで興味を持った以下の論文を読ませていただきました.名前もかっこいい.ヴァニッシングコンポーネントアナリシス!
ICML2013のbestpaper。データ中の集合(例えば画像中の8の字など)が0になるような生成多項式を求める(=集合のコンパクトな表現)効率的なアルゴリズムを提案し教師有学習時の特徴生成などに使える。すごい http://t.co/DedSoyLaJR
— 岡野原 大輔 (@hillbig) June 20, 2013
- “Vanishing Component Analysis” Roi Livni et al, ICML 2013 (Best Paper)
タイミングよく,ICML2013読み会という企画に乗っかるチャンスを頂けたので,今回はそちらでもお話させていただきました.会場には40人ほどいらっしゃったでしょうか.思いのほか多くの方が集まっており,演台から会場をみたときにちょっと圧倒されちゃいました・・・.外部でお話するのはとても久しぶりだったのですが,たいへん楽しい会でした.主催の @sla さん,会場を提供してくださった中川先生,ありがとうございました.
この論文は,PCAやICAに代表されるComponent Analysisに,これまでとはまったく別の角度からアタックした論文です.
PCA,ICAというと,特徴量抽出とか信号分離などによく使われているイメージですね.多くの「なんとかComponent Analysis」はデータの成分がある種の確率分布(多くの場合,正規分布)にしたがって生成されているという仮定に立脚しています.また,見つけることのできる成分(基底といいます)は線形なものに限られることがほとんど.
対してこの論文では,「多項式」で表現されるような基底を抜き出すことに焦点を当てています.無理やり1ページで説明しようとするとこんな感じ.
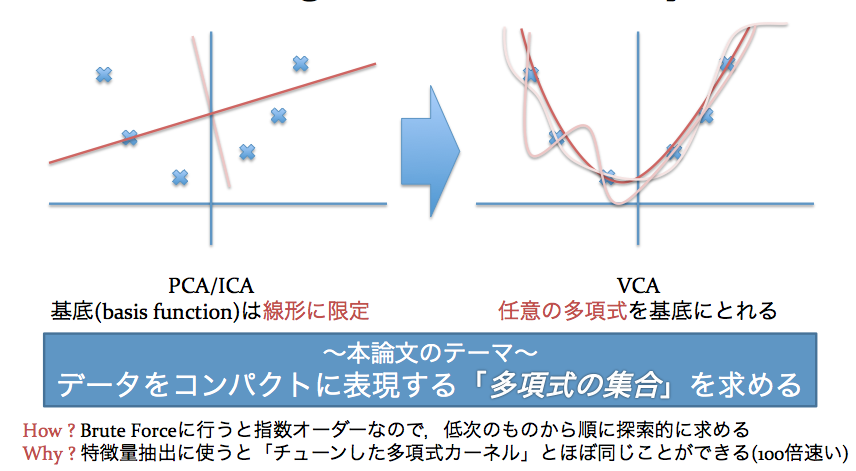
で,興味をもっていただけましたらスライドを眺めていただきたいのですが,この「多項式集合」を特徴量抽出に使うと,いい感じに組み合わせを考慮した素性を抽出することができるようです.しかも,(※多少の前提条件は必要ですが)この方法で抽出した特徴ベクトルを分類問題に適用すると,線形分離できることが保証される,というありがたさ.多項式カーネルを直接用いる分類に比べ,精度がほとんど落ちることなく,分類において最大100倍ほどの高速化を達成しています.
今後もいろいろな展開が考えられる,読んでいて楽しい論文でした.手法や達成した性能自体が凄い,というよりは,これまで機械学習で殆ど用いられてこなかった代数幾何の概念を完成度の高い形で既存の問題設定に組み込んだ.というのがBest Paperとして評価された一因なのかなとも思います.
ICML読み会での発表後にTwitterを眺めていたら,
さっきグレブナー基底とか何とか言ったけど、これはむしろ自由度の高い単なる多項式回帰な気がするので、今からちゃんと読むです… [要出典]
— ぽよ子 (@tara_nai) July 9, 2013
とのご指摘が・・・.これはすずかけ台の勉強会でも指摘されて,ちょっとアレレってなっていた部分でもありました.説明できなくてスミマセン.
未だにアレレってなっているのですが,たしかに問題自体は多項式回帰の枠組みで考えることもできそうです.ただ,効率的にかつ冗長性を抑えながら,できるだけ小さい次数からFilterしていくということを考えると,イデアルのもつ吸収律を活用する,VCAのような枠組みが有効に働いてくるのではないかと思います.(スミマセン,イデアルとはいったい何なのか,グレブナー基底とはいったい何なのか,未だにあんまりわかってないので自信はありません・・・)
ちなみにこのチーム,すでにDeep Learningへの応用を考えていらっしゃるみたいで,そちらのプレプリントも出てたりします.なんともはや.
他の方の発表も興味深い話が盛りだくさんで,すずかけの方では元同期の @tma15 くんがオンラインコミュニティにおける参加者の寿命を言語的特徴から推測する話(WWWのベストペーパー)を紹介してくれたり,ICML読み会のほうは.
- 超多クラスのロジスティック回帰の分散学習
- オンラインのマルチタスク学習(Lifelong Learningというらしいです)の爆速化
- 重みベクトルのビット数をAdaptiveに調節して省メモリに
- ローカルには線形なSVMを多数組み合わせることで非線形分類を高速化
- Deep LearningにおけるRectifierに代わる活性化関数Maxoutの提案
- 高次の共起を考慮にいれたタグの補完に基づいた高速画像タギング
- ビデオ映像からの人間の動作認識
- 複数の目的関数をパレート最適に持っていくようなActive Learning
- あんまり確率的ではないTopic Modelとその特徴付け
などなど(発表の要旨をつかめてなかったらすみません),何でもありな感じでワクテカ.実際の現場で機械学習を応用されてるPFIの方の発表が多かったこともあり,精度を下げずにいかに高速化するか,という方向性の論文が多かったように思います.
個人的には, @sla さんがオープニングで話してくださった,「なんでもi.i.dを仮定するのはそろそろ脱却して,時間/空間に沿って変化するような動的なデータに対しても理論を作っていくべき」というコメントがたいへん興味深く感じました.
機械学習が実世界に浸透していくにしたがって,これからはひとつのモデルなり分類器なりがそれなりに長く使われることを考えなければならない時期にきているのかなとも思います.そういう状況のもとでは,(たとえば言語の話でいえばその時々で流行語があるように)入力の分布がどんどん変わっていくような状況に対してうまく適応していくような問題設定を明確に意識していく必要がありそうです. @unnonouno さんが紹介してくださった,Lifelong Learningも,そういうモチベーションを含んでいるのかな.
私個人としましては,もう長いこと途絶えてしまっている外部へのアウトプットを再開するよい機会になりましたので,今後は知識を頂くだけではなく,自分の学んだことを共有することを心がけていきたいと感じた会でした.
久しぶりにお会いした方もいらっしゃったので,ゆっくりお話できれば良かったのですが,ちょっと事情がありまして早々と帰宅.また近いうちにお会いできる機会があれば幸いです(人生相談にのっていただきたいのでした・・・)